重学操作系统
之前虽然也自己用vps搭搭机场、部署一下自己的小网站啥的,但是对linux和操作系统没有太多深入了解,所以双11在拉钩抢了一些课,随便记记。
这种东西还是要看多用,所以就大概过一遍知识点,有个印象。
计算机组成原理
32位和64位
- 如果是软件,那么我们的数据库有 32 位和 64 位版本;
- 如果是操作系统,那么在阿里云上选择 Centos 和 Debian 版本的时候,也会有 32/64 版本;
- 如果是 CPU,那么有 32 位 CPU,也有 64 位 CPU。
冯诺依曼模型
输入设备
输出设备
内存
CPU(中央处理器)
如果 CPU 每次可以计算 4 个 byte,那么我们称作 32 位 CPU
如果 CPU 每次可以计算 8 个 byte,那么我们称作 64 位 CPU
这里的 32 和 64,称作 CPU 的位宽。
总线
CPU 和内存以及其他设备之间,也需要通信,因此我们用一种特殊的设备进行控制,就是总线。总线分成 3 种:
- 一种是地址总线,专门用来指定 CPU 将要操作的内存地址
- 还有一种是数据总线,用来读写内存中的数据
- 最后一种总线叫作控制总线,用来发送和接收关键信号,比如中断信号,还有设备复位、就绪等信号,都是通过控制总线传输。同样的,CPU 需要对这些信号进行响应,这也需要控制总线
存储器分级策略

假设有一个二维数组,总共有 1M 个条目,如果我们要遍历这个二维数组,应该逐行遍历还是逐列遍历?
逐行遍历会更快。当 CPU 遍历二维数组的时候,会先从 CPU 缓存中取数据。CPU 设计不是每次读取一个内存地址,而是读取每次读取相邻的多个内存地址,
可以二维数组想象成只有一行的一维数组,行坐标增加时,内存空间是跳跃的。列坐标增加时,内存空间是连续的。
SSD、内存和 L1 Cache 相比速度差多少倍?
因为内存比 SSD 快 101000 倍,L1 Cache 比内存快 100 倍左右。因此 L1 Cache 比 SSD 快了 1000100000 倍。所以你有没有发现 SSD 的潜力很大,好的 SSD 已经接近内存了,只不过造价还略高。
Linux指令入门
什么是shell
Shell 把我们输入的指令,传递给操作系统去执行,所以 Shell 是一个命令行的用户界面。
几种常见的文件类型
Linux 把所有的设备都抽象成了文件,比如说打印机、USB、显卡等。这让整体的系统设计变得高度统一。
- 普通文件(比如一个文本文件)没有符号结尾的是普通文件
- 目录文件(目录也是一个特殊的文件,它用来存储文件清单,比如
/也是一个文件) / 结尾的是目录 - 可执行文件(
rm就是一个可执行文件)。* 结尾的是可执行文件 - 管道文件。 | 结尾的管道文件
- Socket 文件。= 结尾的是 Socket 文件
- 软链接文件。@ 结尾的是软链接
- 硬链接文件。= 结尾的是 Socket 文件
文件的增删改查
man
man意思是 manual,就是说明书的意思,这里指的是系统的手册。比如使用man touch就会列出touch命令的详细用法。
touch
touch指令本来是用来更改文件的时间戳的,但是如果文件不存在touch也会帮助创建一个空文件。
touch test.txt
mkdir
增加一个目录
mkdir test
如果要创建的文件夹的父目录不存在,要使用-p参数,这个参数控制mkdir当发现目标目录的父级目录不存在的时候会递归的创建:
mkdir -p test/child-test
ls
ls是 list 的缩写,查看当前目录下所有文件,如果要查看更完善的信息,还可以使用ls -l。-l是ls指令的可选参数。
rm
rm是 remove 的缩写,用于删除一个文件或文件夹。
删除文件:
rm test.txt
删除文件夹,要加-r参数,代表递归删除的意思:
rm -r test
cat
cat指令将文件连接到标准输出流并打印到屏幕上。但是cat不适合用来打印输出大文件。
more
more可以帮助我们分页读取文件。
less
和more差不多,但是可以向上翻页。
head/tail
head和tail是一组,它们用来读取一个文件的头部 N 行或者尾部 N 行。
tail -f
-f是 follow 的意思,就是文件追加的内容会跟随输出到标准输出流。
grep
g就是global,全局;re就是regular expression,正则表达式;p就是pattern模式。
which
可以查询一个指令文件所在的位置。
which go会打印/usr/bin/go
find
find 指令帮助我们在文件系统中查找文件。
可以使用find / -iname "*.txt",/是路径,-iname这个参数是用来匹配查找的,i 字母代表忽略大小写,这里也可以用-name替代
进程
应用的可执行文件是放在文件系统里,启动可执行文件,就会在操作系统里(具体来说是内存中)形成一个应用的副本,这个副本就是进程。
什么是进程(进程的定义是什么)?
进程就是应用的执行副本。
进程的作用是什么?
进程是操作系统分配资源的最小单位。
ps
p代表process,s代表snapshot。
使用此命令可以查看当前的进程。
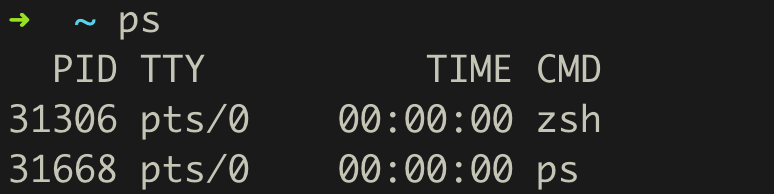
如图有两个进程:
zsh是打开了这个控制台,执行shell的是zsh。ps是使用ps命令启动时,被ps自己捕捉到。
什么是TTY?
操作系统上的 TTY 是一个输入输出终端的概念,比如用户打开
bash,操作系统就为用户分配了一个输入输出终端。
使用-e可以查看操作系统的所有进程, 使用-f可以显示更多的描述字段。如图:

描述字段:
- UID:指进程的所有者。
- PID:进程的唯一标识。
- PPID:父进程的唯一标识。
- C:CPU占用。
- STIME:开始时间。
- TTY:进程所在的TTY,没有就是问号。
- CMD:进程启动时的命令。如果是方括号括起来的,那就是系统进程或内核进程。
top
和ps的区别是,top显示实时数据而不是快照。
htop
比top更强大的一个非自带的工具,需要自己安装。
管道(Pipeline)
管道的作用是在命令和命令之间传递数据,更准确的说是在进程和进程之间传递数据。
输入输出流
每个进程拥有自己的标准输入流,标准输出流,标准错误流。
- 标准输入流:用0表示,可以作为进程执行的上下文,进程执行可以从输入流中获取数据。
- 标准输出流:用1表示,标准输出流的写入结果会被打印到屏幕上。
- 标准错误流:如果进程在执行过程中发生异常,那么异常信息会被记录到标准错误流中。
重定向
>:覆盖重定向>>:追加重定向
ls -l,结果会写入标准输出流,进而被打印,如图:
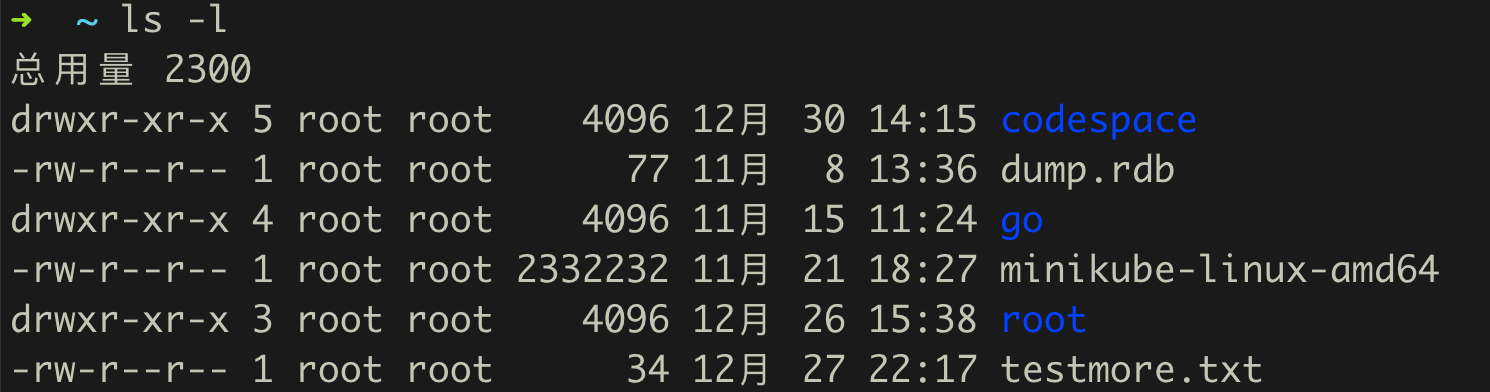
ls -l > out 会把上图的内容存入到out文件,不会在屏幕上打印。
ls -l >> out 会把上图的内容追加存入到out文件,不会在屏幕上打印。
管道的作用和分类
管道和重定向很像,但是管道是一个连接一个进行计算,重定向是将一个文件的内容定向到另一个文件,这二者经常会结合使用。
有两种类型的管道:
- 匿名管道:这种管道也在文件系统中,但是它只是一个存储节点,不属于任何一个目录。说白了,就是没有路径。
- 命令管道:这种管道就是一个文件,有自己的路径。
管道具有FIFO(先进先出)的特性。
管道的使用场景
排序
ls | sort -r -r表示倒序,按照文件名称倒序排列显示。
去重
sort a.txt | uniq,先排序,再将排序结果去重。
筛选
find ./ | grep Spring。find ./ 递归列出当前目录下的文件,grep从输出流中找出包含Spring关键字的行。
find ./ | grep Spring | grep -v MyBatis。grep -v MyBatis代表不包含 MyBatis关键字。
数行数
find ./ -iname "*.js" | wc -l
找到./路径下,所有js文件,然后统计行数。
中间结果
find ./ -iname "*.js" | tee jslist | grep test
找到./路径下,所有js文件,然后存入jslist文件,然后筛选有关键字grep的文件,打印到控制台。
tee这个执行就像英文字母中的 T 一样,连通管道两端,下面又开了口。这个开口,在函数式编程里面叫作副作用。
xargs
xargs指令从标准数据流中构造并执行一行行的指令。
ls | grep jslist | xargs -I gg mv gg prefix_gg
将包含jslist关键字的文件加上prefix前缀,如图:

管道文件
上文中说管道有匿名管道和命名管道,匿名管道通过|就可以创造和使用。
而命名管道是要挂到文件夹中的,因此需要创建。
用mkfifo指令可以创建一个命名管道,如图:

根据一个IP地址列表,逐个ping这些ip,并收集每个IP的延迟等。
cat iplist | xargs -n1 ping -c2 > pinglistres
用户和权限
权限抽象
用户和用户组
linux将用户抽象为账户,账户可以登录系统。
linux支持组,每个用户可以在多个组,可以利用组给用户快速分配权限。
root账户也叫超级管理员账户,他可以使用系统提供的全部能力。
文件权限:
- 读权限
r - 写权限
w - 执行权限
x
然后每个文件又可以从 3 个维度去配置上述的 3 种权限:
- 用户维度。每个文件可以所属 1 个用户,用户维度配置的 rwx 在用户维度生效;
- 组维度。每个文件可以所属 1 个分组,组维度配置的 rwx 在组维度生效;
- 全部用户维度。设置对所有用户的权限。
分析下面两个文件的权限
1 | drwxr-xr-x 5 root root 4096 12月 30 14:15 codespace |
- 第一位
-代表普通文件,d代表目录,p代表管道 rwx代表用户维度,这里是表示codespace的所属用户可以读写和执行这个文件。-
r-x代表用户组维度,这里表示codespace所属用户组里的所有用户可以读和执行这个文件。 r-x代表所有用户可以读和执行这个codespace文件
初始权限问题
一个文件创建后,文件的所属用户会被设置成创建文件的用户
linux中,每个用户创建时,会有一个同名的用户组也被创建,登录后,工作分组默认使用它的同名分组。
使用newgrp指令可以切换到另一个工作分组。
所以文件被创建后的权限通常是:rw-rw-r--
公共执行文件的权限
一个文件权限如果是可执行,但是不可读?那它也无法执行。
1 | ls -l /usr/bin/ls` |
用户分组指令
groups
查看当前用户的分组
groups root可以查看指定用户(root)的分组
id
查看当前用户信息
uid 是用户 id
gid 是组 id
groups 后面是每个分组和分组的 id。对应
groups查看到的分组
cat /etc/passwd
查看所有用户

创建用户
sudo useradd foo
sudo的意思是superuser do,这里表示使用超级管理员的身份去执行这条命令。
创建分组
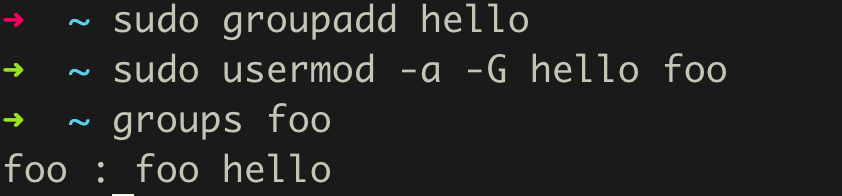
sudo groupadd hello
为用户增加次级分组
组分为主要分组和次级分组。主要分组只有一个(默认创建的用户同名分组?),次级分组可以有多个。
使用sudo usermode -a -G hello foo把我们前面创建的foo用户加入到hello分组中。
-a代表append,-G代表一个次级分组的清单, 最后一个foo是账户名。
这时使用groups foo查看如图所示:
修改用户的主要分组
sudo usermod -g hello foo
文件权限管理指令
查看
ls -l
修改文件权限
1 | 设置foo可以执行 |
因为rwx在 Linux 中用相邻的 3 个二进制位来表示:
第一组是用户权限,第二组是组权限,第三组是所有用户的权限。然后用-代表没有权限。
1 | 设置rwxrwxrwx (111111111 -> 777) |
第一位
-为普通文件:Linux中最多的一种文件类型, 包括 纯文本文件、二进制文件、数据格式的文件(data)、各种压缩文件。d为目录文件:就是目录, 能用cd命令进入的。b为块设备文件:存储数据以供系统存取的接口设备,简单而言就是硬盘。例如一号硬盘的代码是/dev/hda1等文件。
c为字符文件:串行端口的接口设备,例如键盘、鼠标等等。s为套接字文件:通常用在网络数据连接。可以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信,最常在 /var/run目录中看到这种文件类型。
f为管道文件:FIFO也是一种特殊的文件类型,它主要的目的是,解决多个程序同时存取一个文件所造成的错误。FIFO是first-in-first-out(先进先出)的缩写。l为链接文件:类似Windows下面的快捷方式。第一个属性为 [l],例如 [lrwxrwxrwx]。rwx-
r是否可读。 -
w是否可写。 -
x是否可执行。
-
修改文件所属用户
chown foo iplist 修改文件iplist的所属用户为foo
chown foo.hello iplist同时修改文件iplist的所属用户为foo,用户组为hello
使用ls -l iplist:
1 | -rwxr--r-- 1 foo hello 25 1月 8 11:15 iplist |
####网络命令
远程操作指令
ssh(Secure Shell)
ssh user@ip
然后输入密码就可以登录进远程服务器。
ifconfig
查看本地IP以及本地有哪些网络接口
查看本地网络状态
netstat
不传任何参数的netstat帮助查询所有的本地 socket。
socket 是网络插槽被抽象成了文件,负责在客户端、服务器之间收发数据。
查看TCP连接:
netstat -t
查看端口占用:
netstat -ntlp | grep 22
-n是将一些特殊的端口号用数字显示,-t是指看 TCP 协议,-l是只显示连接中的连接,-p是显示程序名称。
网络测试
ping
查看本机到某个网站的网络延迟。
1 | ➜ ~ ping www.baidu.com |
ping一个网站需要使用 ICMP 协议。因此你可以在上图中看到 icmp 序号ttl叫作 time to live,是封包的生存时间。time是往返一次的时间。
telnet
查看本机到某个 IP + 端口的网络是否通畅
1 | ➜ ~ telnet www.baidu.com 443 |
DNS查询
host
查询拉勾网的 DNS:
1 | ➜ ~ host www.lagou.com |
dig
显示的更加详细:
1 | ➜ ~ dig www.lagou.com |
软件的安装
yum
yum是Python 开发的,提供的是rpm包,因此只有redhat系的 Linux,比如 Fedora,Centos 支持yum。yum的主要能力就是帮你解决下载和依赖两个问题。
apt
sudo apt remove vim 删除vim
dpkg -l vim vim 的状态从ii变成了rc,r是期望删除,c是实际上还有配置文件遗留
sudo apt purge vim 可以彻底删除vim
进程和线程
进程和线程
- 进程是软件的副本,是计算机分配资源的最小单位。
- 线程运行在进程里,线程是CPU调度的最小单位。
锁
原子操作
原子操作就是操作不可分。在多线程环境,一个原子操作的执行过程无法被中断。
i++ 由 读取 i 的值、计算 i +1 、把新值赋给 i 。
竞争条件
两个线程并发执行i++

访问共享资源的程序片段我们称为临界区。
cas 指令
很多 CPU 都提供 Compare And Swap 指令。这个指令的作用是更新一个内存地址的值,比如把i更新为i+1,但是这个指令明确要求使用者必须确定知道内存地址中的值是多少。
tas 指令
Test-And-Set 指令(tas)。tas 指令的目标是设置一个内存地址的值为 1,它的工作原理和 cas 相似。
锁
锁(lock),目标是实现抢占(preempt)。就是只让给定数量的线程进入临界区。
自旋锁
1 | function lock(){ |
使用一个while循环获取锁,直到锁被其它线程释放。这种情况线程不会主动释放资源,我们称为自旋锁。
- 优点:不会发生线程切换,因为一直循环执行”空指令”。
- 缺点:比较消耗CPU资源,如果一直拿不到锁,就会一直执行。
生产者消费者模型
Monitor 实现了生产者、消费者模型。
如果一个线程拿到锁,那么这个线程继续执行;
如果一个线程竞争锁失败,Montior 就调用 wait 方法触发生产者的逻辑,把线程加入等待集合;
如果一个线程执行完成,Monitor 就调用一次 notify 方法恢复一个等待的线程。
分布式环境的锁
类似 redis 的 setnx 、setex 等指令。。
乐观锁
类似git提交冲突,假设冲突不会发生,等到发生时再处理。而不是一开始就拒绝(悲观锁)。
线程调度
- 先到先服务
- 短作业优先
- 优先级队列
- 抢占
- 多级队列模型
饥饿和死锁
哲学家就餐问题:

死锁有 4 个基本条件。
资源存在互斥逻辑:每次只有一个线程可以抢占到资源。这里是哲学家抢占叉子。
持有等待:这里哲学家会一直等待拿到叉子。
禁止抢占:如果拿不到资源一直会处于等待状态,而不会释放已经拥有的资源。
循环等待:这里哲学家们会循环等待彼此的叉子。
进程间通信
- 管道 :管道的核心是不侵入、灵活,不会增加程序设计负担,又能组织复杂的计算过程。
- 本地内存共享:共享内存的方式,速度很快,但是程序不是很好写,因为这是一种侵入式的开发。只要不是高性能场景,进程间通信通常不考虑共享内存的方式。
- 本地消息/队列
- 远程调用(rpc): RPC 真正的缺陷是增加了系统间的耦合。当系统主动调用另一个系统的方法时,就意味着在增加两个系统的耦合。长期增加 RPC 调用,会让系统的边界逐渐腐化。
内存管理
垃圾回收 gc
- 引用计数算法(Reference Counter)
- Root Tracing 算法
- 标记-清除(Mark Sweep)算法
- 三色标记-清除算法