由浅入深吃透 Docker
上次在拉钩买的《重学数据结构与算法》感觉讲的还不错,又碰到Docker的课打折,就顺便买了。。
然后主要就是记记笔记整理一下别人的经验用法啥的,这些命令啥的搜都能搜得到。
课程的二维码在最后
Docker 安装
Docekr安装
容器技术原理
chroot
chroot 是在 Unix 和 Linux 系统的一个操作,针对正在运作的软件行程和它的子进程,改变它外显的根目录。一个运行在这个环境下,经由 chroot 设置根目录的程序,它不能够对这个指定根目录之外的文件进行访问动作,不能读取,也不能更改它的内容。
Namespace
Docker 主要用到以下五种命名空间。
pid namespace:用于隔离进程 ID。net namespace:隔离网络接口,在虚拟的 net namespace 内用户可以拥有自己独立的 IP、路由、端口等。mnt namespace:文件系统挂载点隔离。ipc namespace:信号量,消息队列和共享内存的隔离。uts namespace:主机名和域名的隔离。
Cgroups
Cgroups是一种 Linux 内核功能,可以限制和隔离进程的资源使用情况(CPU、内存、磁盘 I/O、网络等)。在容器的实现中,Cgroups通常用来限制容器的 CPU 和内存等资源的使用。
联合文件系统
联合文件系统,又叫
UnionFS,是一种通过创建文件层进程操作的文件系统,因此,联合文件系统非常轻快。Docker 使用联合文件系统为容器提供构建层,使得容器可以实现写时复制以及镜像的分层构建和存储。常用的联合文件系统有AUFS、Overlay和Devicemapper等。
镜像、容器、仓库
镜像
镜像是一个只读的文件和文件夹的组合,是Docker容器启动的先决条件
- 自己创建镜像(
Dockerfile文件) - 从镜像仓库拉去别人的镜像
容器
容器是镜像的运行实体
容器有初建、运行、停止、暂停和删除五种状态
仓库
Docker的镜像仓库类似于代码仓库,用来存储和分发Docker镜像。
Docker 重要组件
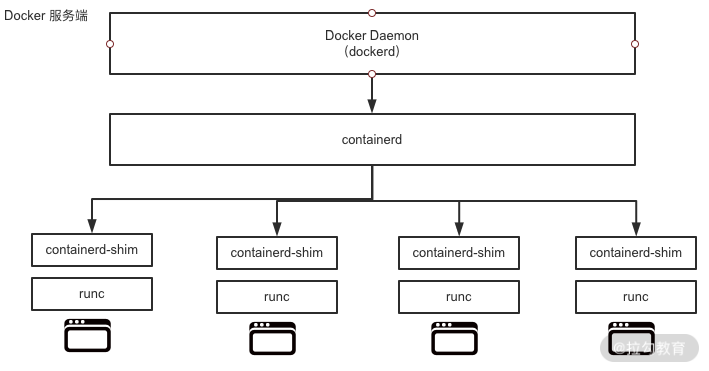
runC是 Docker 官方按照 OCI 容器运行时标准的一个实现。通俗地讲,runC是一个用来运行容器的轻量级工具,是真正用来运行容器的。containerd是 Docker 服务端的一个核心组件,它是从dockerd中剥离出来的 ,它的诞生完全遵循 OCI 标准,是容器标准化后的产物。containerd通过containerd-shim启动并管理runC,可以说containerd真正管理了容器的生命周期。
配置镜像
拉取镜像
docker pull [Registry]/[Repository]/[Image]:[Tag]
查看镜像
docker images ls 查看所有镜像
docker images | grep busybox 使用grep过滤
重命名镜像
docker tag [SOURCE_IMAGE][:TAG][TARGET_IMAGE][:TAG]
docker tag busybox:latest mybusybox:latest 重命名镜像
busybox 和 mybusybox的IMAGE ID相同,它们指向同一个镜像文件,只是别名不同
删除镜像
docker rmi / docker image rm
docker rmi mybusybox:latest 删除busybox镜像
构建镜像
从运行中的容器提交镜像
docker run --rm --name=busybox -it busybox sh创建一个容器- 在容器中执行 :
touch hello.txt && echo "I love Docker. " > hello.txt - 新建窗口执行:
docker commit busybox busybox:hello - 使用
docker image ls查看会有两个版本不同的busybox镜像
使用Dockerfile生成镜像
Dockerfile 指令 |
指令简介 |
|---|---|
| FROM | Dockerfile 除了注释第一行必须是 FROM ,FROM 后面跟镜像名称,代表我们要基于哪个基础镜像构建我们的容器。 |
| RUN | RUN 后面跟一个具体的命令,类似于Linux 命令行执行命令。 |
| ADD | 拷贝本机文件或者远程文件到镜像内 |
| COPY | 拷贝本机文件到镜像内 |
| USER | 指定容器启动的用户 |
| ENTRYPOINT | 容器的启动命令 |
| CMD | CMD 为 ENTRYPOINT 指令提供默认参数,也可以单独使用 CMD 指定容器启动参数 |
| ENV | 指定容器运行时的环境变量,格式为 key=value |
| ARG | 定义外部变量,构建镜像时可以使用 build-arg = 的格式传递参数用于构建 |
| EXPOSE | 指定容器监听的端口,格式为 [port]/tcp 或者 [port]/udp |
| WORKDIR | 为 Dockerfile 中跟在其后的所有 RUN、CMD、ENTRYPOINT、COPY 和 ADD 命令设置工作目录。 |
1 | FROM centos:7 // 基于 centos:7 这个镜像来构建自定义镜像。这里需要注意,每个 Dockerfile 的第一行除了注释都必须以 FROM 开头。 |
容器
什么是容器
容器是基于镜像创建的可运行实例,并且单独存在,一个镜像可以创建多个容器。
容器的生命周期

对容器来说,杀死容器中的主进程(1号进程),容器也会被杀死。
进入容器
docker attach
使用docker attach 命令同时在多个终端运行时,所有的终端窗口将同步显示相同内容,当某个命令行窗口的命令阻塞时,其它命令行窗口同样也无法操作。
所以不推荐使用。
docker exec
使用dokcer exec -it [name]/[id]
删除容器
使用docker rm命令删除一个停止状态的容器。
docker rm busybox
删除正在运行中的容器,必须添加-f / -force 参数
docker rm -f busybox
导出容器
进入容器创建文件
docker exec -it busybox sh
cd /tmp && touch test
执行导出命令
docker export busybox > busybox.tar
导入容器
使用docker import命令导入上一步导出的容器
docker import busybox.tar busybox:test
使用docker run 启动并进入容器,查看上一步创建的临时文件
docker run -it busybox:test sh
cd /temp/ && ls
总结
镜像:镜像包含了容器运行所需要的文件系统结构和内容,是静态的只读文件。
容器:容器是在镜像的只读层上创建了可写层,并且容器中的进程属于运行状态,容器是真正的应用载体。
思考:
容器文件系统为什么要设计成写时复制,而不是每一个容器都单独拷贝一份镜像文件?
我觉得主要是为了节省磁盘空间吧。。
如何编写 Dockerfile
Dockerfile书写原则
- 单一职责:: 不同功能的应用应该尽量拆分成为不同的容器,每个容器只负责单一业务进程。
- 提供注释信息: 晦涩难懂的代码尽量添加注释。
- 保持容器最小化: 应该避免安装无用的软件包。
- 合理选择基础镜像: 容器的核心是应用,只要基础镜像能够满足应用的运行环境即可。
- 使用
.dockerignore文件: 类似.gitignore,忽略掉一些不需要构建的文件。 - 尽量使用构建缓存
- 正确设置时区
- 使用国内软件源加快镜像构建速度
- 最小化镜像层数: 尽可能减少
Dockerfile指令行数,能合并的就合并。
指令书写建议
Run
- 当
RUN指令后面跟的内容比较复杂时,建议使用反斜杠(\)结尾并且换行 RUN指令后面的内容尽量按照字母顺序排序,提高可读性
1 | FROM centos:7 |
CMD 和 ENTRYPOINT
区别
ENTRYPOINT指令可以结合CMD指令使用,也可以单独使用,而CMD指令只能单独使用。Dockerfile中如果使用了ENTRYPOINT指令,启动Docker容器时需要使用--entrypoint参数才能覆盖Dockerfile中的ENTRYPOINT指令 ,而使用CMD设置的命令则可以被docker run后面的参数直接覆盖。
如果你希望你的镜像足够灵活,推荐使用CMD指令。
如果你的镜像只执行单一的具体程序,并且不希望用户在执行docker run时覆盖默认程序,建议使用ENTRYPOINT。
无论使用CMD还是ENTRYPOINT,都尽量使用exec模式。
ADD 和 COPY
ADD支持更多文件来源类型,比如自动提取tar包,并且可以支持源文件为URL格式。COPY指令只支持基本的文件和文件夹拷贝功能
但是不推荐使用ADD 向容器中添加URL文件:
1 | ADD http://pyropus.ca/software/memtester/old-versions/memtester-4.3.0.tar.gz /tmp/ |
应该这样写:
1 | RUN wget -O /tmp/memtester-4.3.0.tar.gz http://pyropus.ca/software/memtester/old-versions/memtester-4.3.0.tar.gz \ |
WORKDIR
为了使构建过程更加清晰明了,推荐使用 WORKDIR 来指定容器的工作路径
应该尽量避免使用 RUN cd /work/path && do some work这样的指令。
基于内核的弱隔离系统如何保障安全性
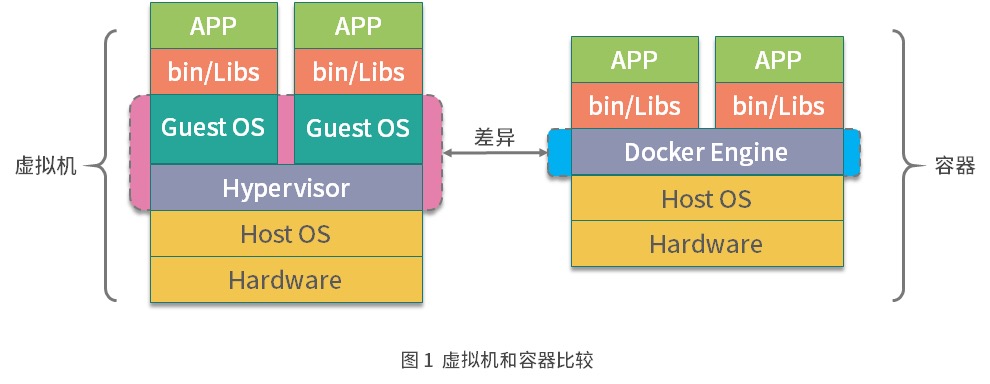
Docker 与虚拟机区别
###常用解决方案

资源隔离
什么是Namespace
Namespace 是 Linux 内核的一个特性,该特性可以实现在同一主机系统中,对进程 ID、主机名、用户 ID、文件名、网络和进程间通信等资源的隔离。Docker 利用 Linux 内核的 Namespace 特性,实现了每个容器的资源相互隔离,从而保证容器内部只能访问到自己 Namespace 的资源。
Docker使用的各Namespace的作用
Mount Namespace
隔离不同进程或进程组看到的挂载点,实现容器内只能看到自己的挂载信息,在容器内的挂载操作不会影响到主机目录。
使用unshare --mount --fork /bin/bash命令可以新建Mount Namespace。
Pid Namespace
用于隔离进程
使用unshare --pid --fork --mount-proc /bin/bash
UTS Namespace
用于隔离主机名
使用unshare --mount --fork /bin/bash
使用hostname命令查看主机名
IPC Namespace
IPC Namespace 主要是用来隔离进程间通信的。
PID Namespace 和 IPC Namespace 一起使用可以实现同一 IPC Namespace 内的进程彼此可以通信,不同 IPC Namespace 的进程却不能通信。
使用unshare --ipc --fork /bin/bash
User Namespace
用来隔离用户和用户组。
以非 root 用户运行的进程可以在一个单独的 User Namespace 中映射成 root 用户。使用 User Namespace 可以实现进程在容器内拥有 root 权限,而在主机上却只是普通用户。
使用unshare --user -r /bin/bash
Net Namespace
用来隔离网络设备、IP 地址和端口等信息。
Net Namespace 可以让每个进程拥有自己独立的 IP 地址,端口和网卡信息。例如主机 IP 地址为 172.16.4.1 ,容器内可以设置独立的 IP 地址为 192.168.1.1。
ps: Namespace中没有进程时会自动删除,无需手动删除。如果 namespace 对应的文件某个应用程序打开,那么该 namespace 是不会被删除的,这个特性可以让我们保持住某个 namespace,以便后面往里面添加进程。
##资源限制
使用Namespace技术可以实现容器中的进程看不到别的容器的资源。但是容器内的进程仍然可以自由使用主机的CPU、内存等资源。
所以我们要使用cgroups来限制容器的资源使用。
什么是cgroups
cgroups(全称:control groups)是 Linux内核的一个功能,它可以实现限制进程或者进程组的资源(如 CPU、内存、磁盘 IO 等)。
功能:
- 资源限制: 限制资源的使用量
- 优先级控制:不同组可以有不同的资源使用优先级
- 审计:计算控制组的资源使用情况
- 控制:控制进程的恢复和挂起
核心概念:
- 子系统(subsystem):一个子系统代表一类资源调度控制器,例如,内存子系统可以限制内存使用量,cpu子系统可以限制cpu的使用时间等。
- 控制组(cgroup):表示一组进程和一组带有参数的子系统的关联关系。
- 层技术(hierarchy):是由一系列的控制组按照树状结构排列组成的,子控制组默认拥有父控制组的属性。
Docker是如何使用cgroups的
首先,使用如下命令,创建一个限制内存为1G的容器
docker run -it -m=1g nginx
查看文件目录
ls -l /sys/fs/cgroup/memory
进入docker目录
cd /sys/fs/cgroup/memory/docker
有一个名为容器id的文件夹
cat e3b99e0851f3a732e9a4a894a3137282c0ee421c24bf1275042d9437a122c9c4/memory.limit_in_bytes
显示1073741824
请注意 cgroups 虽然可以实现资源的限制,但是不能保证资源的使用。例如,cgroups 限制某个容器最多使用 1 核 CPU,但不保证总是能使用到 1 核 CPU,当 CPU 资源发生竞争时,可能会导致实际使用的 CPU 资源产生竞争。
组件组成
Docker 整体架构采用 C/S(客户端 / 服务器)模式,主要由客户端和服务端两大部分组成。客户端负责发送操作指令,服务端负责接收和处理指令。

Docker组件剖析
Docker相关组件
docker
docker 是 Docker 客户端的一个完整实现。用户可以通过docker命令完成所有的与服务端的通信。
dockerd
dockerd 是 Docker 服务端的后台常驻进程,用来接收客户端发送的请求,执行具体的处理任务,处理完成后将结果返回给客户端。
docker-init
在执行 docker run 启动容器时可以添加 --init 参数,此时 Docker 会使用 docker-init 作为1号进程,帮你管理容器内子进程,例如回收僵尸进程等。
docker-proxy
docker-proxy 主要是用来做端口映射的。当我们使用 docker run 命令启动容器时,如果使用了 -p 参数,docker-proxy 组件就会把容器内相应的端口映射到主机上来,底层是依赖于 iptables 实现的。
containerd相关组件
containerd
containerd 组件是从 Docker 1.11 版本正式从 dockerd中剥离出来的,它的诞生完全遵循 OCI 标准,是容器标准化后的产物。containerd 完全遵循了 OCI 标准,并且是完全社区化运营的,因此被容器界广泛采用。
containerd 不仅负责容器生命周期的管理,同时还负责一些其他的功能:
镜像的管理,例如容器运行前从镜像仓库拉取镜像到本地;
接收
dockerd的请求,通过适当的参数调用runc启动容器;管理存储相关资源;
管理网络相关资源。
containerd 包含一个后台常驻进程,默认的 socket 路径为 /run/containerd/containerd.sock,dockerd 通过 UNIX 套接字向 containerd 发送请求,containerd 接收到请求后负责执行相关的动作并把执行结果返回给 dockerd。
如果你不想使用 dockerd,也可以直接使用 containerd 来管理容器,由于 containerd 更加简单和轻量,生产环境中越来越多的人开始直接使用 containerd 来管理容器。
Containerd-shim
containerd-shim 的意思是垫片,类似于拧螺丝时夹在螺丝和螺母之间的垫片。containerd-shim 的主要作用是将 containerd 和真正的容器进程解耦,使用 containerd-shim 作为容器进程的父进程,从而实现重启 containerd 不影响已经启动的容器进程。
ctr
ctr 实际上是 containerd-ctr,它是 containerd 的客户端,主要用来开发和调试,在没有dockerd 的环境中,ctr 可以充当 docker 客户端的部分角色,直接向 containerd 守护进程发送操作容器的请求。
容器运行时组件runc
runc 是一个标准的 OCI 容器运行时的实现,它是一个命令行工具,可以直接用来创建和运行容器。
containerd也是通过runc来实际运行容器。
示例:
准备容器运行时文件:
1 | cd /home/centos |
生成 runc config 文件:
1 | runc spec |
启动busybox容器:
1 | runc run busybox |
打开一个命令行窗口,可以使用 run list 命令看到刚才启动的容器:
1 | run list |
总结

网络模型
CNM
CNM (Container Network Model) 是 Docker 发布的容器网络标准,意在规范和指定容器网络发展标准,CNM 抽象了容器的网络接口 ,使得只要满足 CNM 接口的网络方案都可以接入到 Docker 容器网络,更好地满足了用户网络模型多样化的需求。
CNM 定义的网络标准包含三个重要元素。
- 沙箱(Sandbox):沙箱代表了一系列网络堆栈的配置,其中包含路由信息、网络接口等网络资源的管理,沙箱的实现通常是 Linux 的 Net Namespace,但也可以通过其他技术来实现,比如 FreeBSD jail 等。
- 接入点(Endpoint):接入点将沙箱连接到网络中,代表容器的网络接口,接入点的实现通常是 Linux 的 veth 设备对。
- 网络(Network):网络是一组可以互相通信的接入点,它将多接入点组成一个子网,并且多个接入点之间可以相互通信。
Libnetwork
Libnetwork 是 Docker 启动容器时,用来为 Docker 容器提供网络接入功能的插件,它可以让Docker 容器顺利接入网络,实现主机和容器网络的互通。下面,
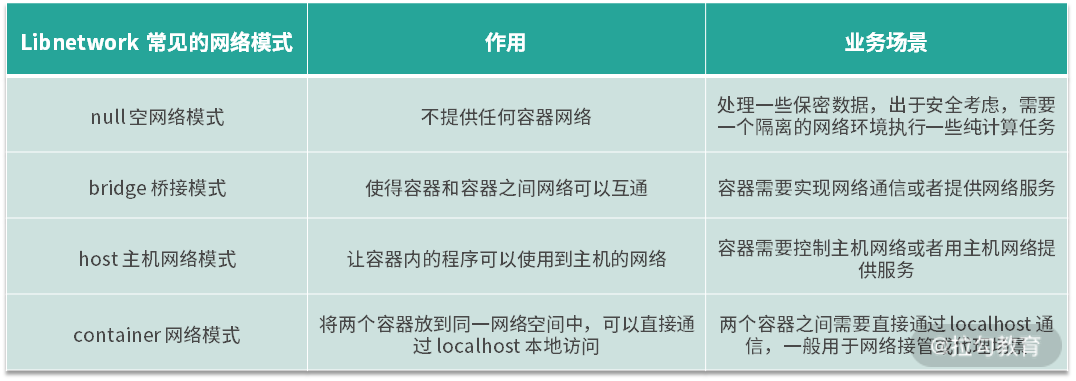
Libnetwork 常见网络模式
null 空网络模式:可以帮助我们构建一个没有网络接入的容器环境,以保障数据安全。
bridge 桥接模式:可以打通容器与容器间网络通信的需求。
host 主机网络模式:可以让容器内的进程共享主机网络,从而监听或修改主机网络。
container 网络模式:可以将两个容器放在同一个网络命名空间内,让两个业务通过 localhost 即可实现访问。
数据存储
Docker 卷的操作

Docker 卷的实现原理
镜像和容器的文件系统原理:
镜像是由多层文件系统组成的,当我们想要启动一个容器时,Docker会在镜像上层创建一个可读写层,容器中的文件都工作在这个读写层中,当容器删除时,与容器相关的工作文件将全部丢失。
实例:
创建一个名称为 volume-data 的卷:
1 | docker volume create volume-data |
使用 ls 命令查看一下/var/lib/docker/volumes 目录下的内容:
1 | ls -l /var/lib/docker/volumes |
然后再看下 volume-data目录下有什么内容:
1 | ls -l /var/lib/docker/volumes/volume-data |
启动一个容器,并且绑定volume-data 卷到容器内的 /data 目录下:
1 | docker run -it --mount source=volume-data,target=/data busybox |
进入到容器的 /data 目录,创建一个 data.log 文件:
1 | cd data/ |
新打开一个命令行窗口,查看一下主机上的文件内容:
1 | ls -l /var/lib/docker/volumes/volume-data/_data |
文件存储驱动AUFS
什么是联合文件系统
联合文件系统(Union File System)是一种分层的轻量级文件系统,它可以把多个目录内容联合挂载到同一目录下,从而形成一个单一的文件系统
联合文件系统是Docker 镜像和容器的基础,因为它可以使 Docker 可以把镜像做成分层的结构,从而使得镜像的每一层可以被共享。
如何配置AUFS
查看系统是否支持AUFS
1 | grep aufs /proc/filessystems |
如果出现:
1 | nodev aufs |
说明系统支持AUFS,一般Ubuntu和Debian操作系统下使用AUFS,centos系统需要单独安装AUFS模块。
当系统支持AUFS时,配置启动参数,在/etc/docker新建daemon.json:
1 | { |
重启docker:
1 | systemctl restart docker |
使用docker info 查看Storage Driver是否变为aufs
AUFS是如何存储文件的
AUFS 是联合文件系统,意味着它在主机上使用多层目录存储,每一个目录在 AUFS 中都叫作分支,而在Docker 中则称之为层(layer),但最终呈现给用户的则是一个普通单层的文件系统,我们把多层以单一层的方式呈现出来的过程叫作联合挂载。

文件存储驱动Devicemapper
什么是 Devicemapper
Devicemapper 是 Linux 内核提供的框架,从 Linux 内核 2.6.9 版本开始引入,Devicemapper 与 AUFS 不同,AUFS 是一种文件系统,而Devicemapper 是一种映射块设备的技术框架。
Devicemapper 的关键技术
用户空间负责配置具体的设备映射策略与相关的内核空间控制逻辑,例如逻辑设备 dm-a 如何与物理设备 sda 相关联,怎么建立逻辑设备和物理设备的映射关系等。
内核空间则负责用户空间配置的关联关系实现,例如当 IO 请求到达虚拟设备 dm-a 时,内核空间负责接管 IO 请求,然后处理和过滤这些 IO 请求并转发到具体的物理设备 sda 上。
Devicemapper 的工作机制主要围绕三个核心概念
- 映射设备(mapped device):即对外提供的逻辑设备,它是由 Devicemapper 模拟的一个虚拟设备,并不是真正存在于宿主机上的物理设备。
- 目标设备(target device):目标设备是映射设备对应的物理设备或者物理设备的某一个逻辑分段,是真正存在于物理机上的设备。
- 映射表(map table):映射表记录了映射设备到目标设备的映射关系,它记录了映射设备在目标设备的起始地址、范围和目标设备的类型等变量。

文件存储驱动OverlayFS
使用 overlay2 的先决条件
要想使用overlay2,Docker 版本必须高于 17.06.02。
如果你的操作系统是 RHEL 或 CentOS,Linux 内核版本必须使用 3.10.0-514 或者更高版本,其他 Linux 发行版的内核版本必须高于 4.0(例如 Ubuntu 或 Debian),你可以使用uname -a查看当前系统的内核版本。
overlay2最好搭配 xfs 文件系统使用,并且使用 xfs 作为底层文件系统时,d_type必须开启,可以使用以下命令验证 d_type 是否开启:
Docker Compose
编写 Docker Compose 模板文件
在使用 Docker Compose 启动容器时, Docker Compose 会默认使用 docker-compose.yml 文件, docker-compose.yml 文件的格式为 yaml(类似于 json,一种标记语言)。
Docker Compose 模板文件一共有三个版本: v1、v2 和 v3。目前最新的版本为 v3,也是功能最全面的一个版本,下面我主要围绕 v3 版本介绍一下如何编写 Docker Compose 文件。
Docker Compose 文件主要分为三部分: services(服务)、networks(网络) 和 volumes(数据卷):
services(服务):服务定义了容器启动的各项配置,就像我们执行docker run命令时传递的容器启动的参数一样,指定了容器应该如何启动,例如容器的启动参数,容器的镜像和环境变量等。networks(网络):网络定义了容器的网络配置,就像我们执行docker network create命令创建网络配置一样。volumes(数据卷):数据卷定义了容器的卷配置,就像我们执行docker volume create命令创建数据卷一样。
文件结构:
1 | version: "3" |
使用 Docker Compose 管理 WordPress
创建项目目录
1 | mkdir /tmp/wordpress && cd /tmp/wordpress |
创建 docker-compose.yml 文件
1 | touch docker-compose.yml |
编写:
1 | version: '3' |
启动:
1 | docker-compose up -d |
等待启动完成访问localhost:8080即可进入wordpress安装界面:
Docker Swarm
优点:
分布式:
Swarm使用Raft(一种分布式一致性协议)协议来做集群间数据一致性保障,使用多个容器节点组成管理集群,从而避免单点故障。安全:
Swarm使用TLS双向认证来确保节点之间通信的安全,它可以利用双向TLS进行节点之间的身份认证,角色授权和加密传输,并且可以自动执行证书的颁发和更换。简单:
Swarm的操作非常简单,并且除Docker外基本无其他外部依赖,而且从Docker 1.12版本后,Swarm直接被内置到了Docker中,可以说真正做到了开箱即用。
架构

Kubernetes
Kubernetes 架构
Kubernetes 采用典型的主从架构,分为 Master 和 Node 两个角色。
Mater是Kubernetes集群的控制节点,负责整个集群的管理和控制功能。- kube-apiserver:
kube-apiserver的所有数据都存储在etcd中,etcd是一种采用 Go 语言编写的高可用 Key-Value 数据库,由 CoreOS 开发 - kube-scheduler
- kube-controller-manager
- kube-apiserver:
Node为工作节点,负责业务容器的生命周期管理。- kubelet
- kube-proxy

Kubernetes 核心概念
集群
集群是一组被 Kubernetes 统一管理和调度的节点,被 Kubernetes 纳管的节点可以是物理机或者虚拟机。集群其中一部分节点作为 Master 节点,负责集群状态的管理和协调,另一部分作为 Node 节点,负责执行具体的任务,实现用户服务的启停等功能。
标签(Label)
Label 是一组键值对,每一个资源对象都会拥有此字段。Kubernetes 中使用 Label 对资源进行标记,然后根据 Label 对资源进行分类和筛选。
命名空间(Namespace)
Kubernetes 中通过命名空间来实现资源的虚拟化隔离,将一组相关联的资源放到同一个命名空间内,避免不同租户的资源发生命名冲突,从逻辑上实现了多租户的资源隔离。
容器组(Pod)
Pod 是 Kubernetes 中的最小调度单位,它由一个或多个容器组成,一个 Pod 内的容器共享相同的网络命名空间和存储卷。Pod 是真正的业务进程的载体,在 Pod 运行前,Kubernetes 会先启动一个 Pause 容器开辟一个网络命名空间,完成网络和存储相关资源的初始化,然后再运行业务容器。
部署(Deployment)
Deployment 是一组 Pod 的抽象,通过 Deployment 控制器保障用户指定数量的容器副本正常运行,并且实现了滚动更新等高级功能,当我们需要更新业务版本时,Deployment 会按照我们指定策略自动的杀死旧版本的 Pod 并且启动新版本的 Pod。
状态副本集(StatefulSet)
StatefulSet 和 Deployment 类似,也是一组 Pod 的抽象,但是 StatefulSet 主要用于有状态应用的管理,StatefulSet 生成的 Pod 名称是固定且有序的,确保每个 Pod 独一无二的身份标识。
守护进程集(DaemonSet)
DaemonSet 确保每个 Node 节点上运行一个 Pod,当我们集群有新加入的 Node 节点时,Kubernetes 会自动帮助我们在新的节点上运行一个 Pod。一般用于日志采集,节点监控等场景。
任务(Job)
Job 可以帮助我们创建一个 Pod 并且保证 Pod 的正常退出,如果 Pod 运行过程中出现了错误,Job 控制器可以帮助我们创建新的 Pod,直到 Pod 执行成功或者达到指定重试次数。
服务(Service)
Service 是一组 Pod 访问配置的抽象。由于 Pod 的地址是动态变化的,我们不能直接通过 Pod 的 IP 去访问某个服务,Service 通过在主机上配置一定的网络规则,帮助我们实现通过一个固定的地址访问一组 Pod。
配置集(ConfigMap)
ConfigMap 用于存放我们业务的配置信息,使用 Key-Value 的方式存放于 Kubernetes 中,使用 ConfigMap 可以帮助我们将配置数据和应用程序代码分开。
加密字典(Secret)
Secret 用于存放我们业务的敏感配置信息,类似于 ConfigMap,使用 Key-Value 的方式存在于 Kubernetes 中,主要用于存放密码和证书等敏感信
ps: 看到后面就完全是读ppt了。。感觉讲的一般。
课程二维码
