nodejs必知必会
前言
怎么说呢,很多东西其实之前都整理过,但那是一个学习的过程,很多东西不够准确、严谨。突然就想把看过学过的零散知识重新整理一遍。
JavaScript基础问题
类型
类型判断
typeof操作符
一般数据类型
1 | typeof undefined; // undefined |
特殊的数据类型
1 | typeof null; // object 因为null是一个空对象 |
instanceof操作符
instanceof操作符主要用来检查构造函数的原型是否在对象的原型链上。
1 | const s = new String('123'); |
接下来让我们搞点事情:
1 | s.__proto__ = Object.prototype; // 这是把s变量的原型链指向,Object的原型链。 |
利用instanceof操作符,我们可以对自定义的对象进行判断:
1 | function Animal (name) { |
constructor属性
实际上我们也可以通过constructor属性来达到类型判断的效果:
1 | fizz instanceof Animal // true |
toString方法
利用toString方法基本上可以解决所有内置对象类型的判断:
1 | function type (obj) { |
类型比较
全等===
- 全等不会进行类型转换,类型不相等就是false。
- 类型相等之后会再去比较数值。
- 基本数据类型
number、string、boolean会直接比较值。 - 引用数据类型
Object、Array、Function会比较地址。
- 基本数据类型
+0和-0是全等的,NaN和NaN是不全等的。
相等==
被比较值A \ 被比较值B | undefined | null | Number | String | Boolean | Object |
| :——————-: | :——-: | :–: | :—-: | —- | :— | —- |
| undefined | true | true | false | false | false | IsFalsy(B) |
| null | true | true | false | false | false | IsFalsy(B) |
| Number | false | false | A === B | A === ToNumber(B) | A === ToNumber(B) | A== ToPrimitive(B) |
| String | false | false | ToNumber(A)===B | A === B | ToNumber(A)===ToNumber(B) | A== ToPrimitive(B) |
| Boolean | false | false | ToNumber(A)===B | ToNumber(A)===ToNumber(B) | A === B | ToNumber(A) == ToPrimitive(B) |
| Object | false | false | ToPrimitive(A) == B | ToPrimitive(A) == B | ToPrimitive(A) == ToNumber(B) | A === B |
相等的比较规则是:
先检查类型是否相同,类型相同直接进行全等比较,类型不同根据上表中规则进行类型转化,在进行全等比较。但不是所有的类型都满足上述规则。
- Object类型转为原始值之后,使用的相等和其他值进行比较。就是说要再比较类型,转换类型,再进行全等比较。
- undefined和null是相等的。并且一般情况下,他们不和其他任何类型的数据相等。但是当有类似于
document.all这种效仿undefined对象时,他们相等。
转换规则:
ToNumber(A)尝试在比较前将参数 A 转换为数字。ToPrimitive(A)通过尝试调用 A 的A.toString()和A.valueOf()方法,将参数 A 转换为原始值。
Object.is(value1,value2)
Object.is()判断两个值是否相同。如果下列任何一项成立,则两个值相同:
与相等(==)和全等(===)不同点s
- 与普通
==不同的是,Object.is()不会对数据进行数据类型转换。 - 与全等
===不同的是,Object.is(NaN,NaN)结果是true,而Object.is(-0,+0)结果是false。这与全等(===)刚好相反。
作用域
关于作用域的问题《你不知道的 JavaScript》 讲的很好, 推荐细读。这里只说一下简单围绕var、let、const说一下。
var和let的区别
详情请看阮一峰老师的es6教程,这里大概说几个常用的区别。
- let声明的变量只在当前块有效。
1 | // let变量只在块中生效 |
- let不存在变量提升。
1 | // 变量提升 |
- let声明变量有暂时性死区。let声明变量后,这个变量就和当前块绑定,不受外部影响。一般只要遵循先声明后使用的规范,就不会有这种问题。
1 | var tmp = 123; |
- let变量不允许重复声明。
1 | function func1() { |
1 | function func(arg) { |
- 大多数情况下,强烈建议,在函数中,尤其是for循环中使用let。因为var很容易造成一些不必要的bug。
1 | var tmp = new Date(); |
1 | let a = 1 |
1 | var s = 'hello'; |
- let可以代替匿名自执行函数的写法,当你在for循环中调用一个异步方法时,它使用的总是循环变量的最终值。
1 | for (var i = 0; i < 10; i++) { |
const
- const声明一个只读变量一旦声明,常量的值就不能变,如果再次声明会报错。
1 | const a = 1; |
const变量声明时,必须初始化,不能留到后面赋值
const和let一样,只在块级作用域生效,不存在变量提升,存在暂时性死区
1 | const a = 10; |
- const 变量声明变量不可变的本质。
基本数据类型,值存在栈中,const声明时,变量值不可改变。
引用数据类型,值在堆中,栈中只是一个指向这个值在堆中的一个地址,不可改变的是这个地址,而不是堆中的值。
1 | const a = []; |
如果要彻底冻结一个对象,使用Object.freeze方法。
1 | const foo = Object.freeze({}); |
闭包
详情见 阮一峰老师的闭包讲解
通俗来讲,就是函数外部是无法访问函数内部的变量,但是通过闭包处理,就可以在函数外部访问函数内部的变量。
引用轮子哥的话: 闭包不是私有,闭的意思不是“封闭内部状态”,而是”封闭外部状态“。
举个列子,栗子中的
f2函数就是闭包:1
2
3
4
5
6
7
8
9
10
11
12
13function f1() {
var n = 999;
function f2() {
return n
}
return f2()
}
let b = f1();
console.log(b); // 999
console.log(n) // ReferenceError: n is not defined
值传递和引用传递?
基本概念
先来看一张图
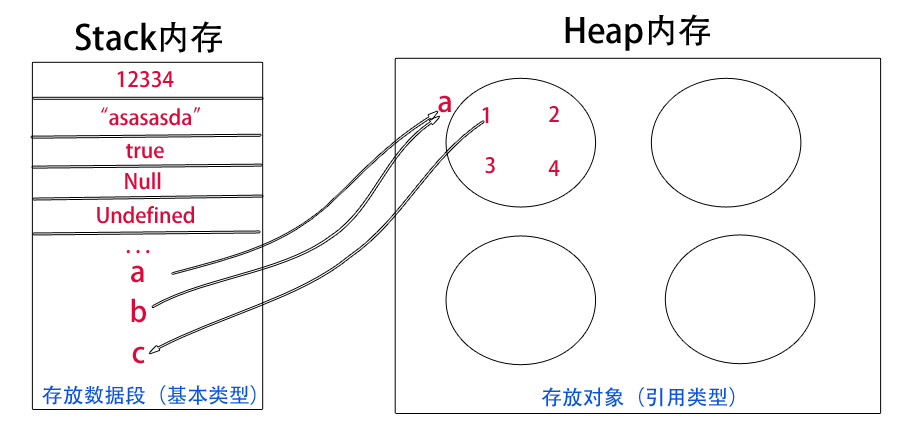
- 由图可知,非基本类型,栈内存储的是实际值在堆中的一个地址,通过这个地址找到实际的值。
- 关于引用传递和传引用,js到有没有传引用,移步js之你不知道的引用传递
深拷贝和浅拷贝
深拷贝和浅拷贝是对JavaScript “引用传递” 的一种应用。
假设你要将一个对象复制给另一个对象。
1
2
3
4
5
6
7
8let obj = {
name: 'zm'
}
let obj2 = obj;
obj2.name = 'ruomu';
console.log(obj); // { name: 'ruomu' } 为什么我修改obj2的值,但是obj也变了呢。。因为其实他们存储了相同的地址值,指向了堆内同一对象。1
2
3
4
5
6
7
8
9
10let obj = {
name: 'zm'
}
let obj2 = {
name: obj.name
};
obj2.name = 'ruomu';
console.log(obj); // { name: 'zm' } 可以看到这里就不会被修改了,因为基础类型存储在栈中,修改就是直接修改栈中的值。所以使用对象赋值时要非常小心,因为node是异步的,不知道在哪里就修改了那个对象,会引起很多bug。所以通常我们想copy一个对象时,需要一些特殊的处理来达到目的。深拷贝和浅拷贝
- 上面的连接有几种写好的深度拷贝方法,就不重复造轮子了。当然最简单的当然是
JSON.parse(JSON.stringify(obj))。
- 上面的连接有几种写好的深度拷贝方法,就不重复造轮子了。当然最简单的当然是
内存
v8内存的大小
- 64位下新生代的空间为64MB,老生代为1400MB。
- 32为下新生代的空间为16MB,老生代为700MB。
- 修改新生代和老生代内存的方式
- **
--max_semi_space_size=xxxx**。修改新生代内存,单位为KB - **
--max-old-space-size=xxxx**。修改老生代内存,单位为MB
- **
v8内存清理机制
- V8的垃圾回收机制和内存限制
- 新生代,牺牲空间换时间,只能使用新生代一半的内存。
- 最开始的变量放在新生代的from空间
- 执行垃圾回收时,将存活的对象从新生代的from空间放到to空间,非存活对象会被释放。
- 完成从from到to空间的复制后,from空间和to空间会发生角色互换。
- 对象晋升
- 对象晋升发生的时间是在,将新生代from空间中存活的对象复制到to空间的时候。
- 对象晋升的条件是:
- 新生代to空间的占用率达到25%以上,对象直接被放入老生代空间中。
- 对象已经经历过一次新生代空间(Scavenge)的回收。
- 老生代空间
- 老生代空间的对象一般都是存活时间比较久的对象,所以如果采用新生代空间的
Scavenge算法,复制对象效率会很低,而且空间会浪费一半。所以v8老生代空间主要采用了Mark-Sweep和Mark-Compact相结合的方式进行垃圾回收。 - Mark-Sweep是标记清除的意思,它分为标记阶段和清除阶段。它最大的问题是,清理完成后,内存空间会不连续。
- 标记阶段。遍历堆中所有的对象,并标记活着的对象。
- 清除阶段。清除没有被标记的对象。
- Mark-Compact是标记整理的意思,它分为标记,整理,清除三步。它的问题是速度比较慢,但是内存空间是连续的。
- 标记和Mark-Sweep一样
- 整理。将活着的对象往一端移动。
- 清除。活着的对象移动完成后,清除掉边界外的内存。
- 老生代空间的对象一般都是存活时间比较久的对象,所以如果采用新生代空间的
如何高效的使用内存
内存被释放条件是,该对象没有被引用。
全部变量的释放条件是进程退出。所以全部变量会长时间存在于老生代内存中,所以尽量少定义全局变量,并及时对全局变量进行释放。
global.foo = undefined或者delete global.foo- 上面两种方式并不会释放掉原本
global.foo指向的对象,而是取消对其的引用,在下一次gc的时候,如果没有其他指向其的引用,那么就会被释放。
闭包可以实现外部作用域访问内部作用域中的变量。
1
2
3
4
5
6
7
8
9
10
11
12function f1() {
var n = 999;
function f2() {
return n
}
return f2()
}
let b = f1();
console.log(b); // 999引用上面闭包用到的一段代码。正常情况下,f1执行完成后,函数作用域内的变量都会随着作用域的销毁而被回收。但是这里的
b保持对f2的引用,而f2访问了变量n,所以这里的函数和变量都不会被释放。滥用闭包是内存泄露的重要原因之一。
内存泄露
内存泄露的排查还是比较复杂,需要配合日志和性能监控工具排查,这里只简单说几种情况。
- 缓存。(请使用redis或者buffer)
- 消费队列。(同上)
- 作用域未释放。(闭包)
- cnode上面一个大佬写的轻松排查线上Node内存泄漏问题
性能监控
看了下,网上关于node内存监控的东西很少,但最后试了下还是alinode最方便,对代码没有侵入。5分钟入门alinode
- 安全问题。alinode好像没有开源,但是部署在本机上给alinode上传数据的agenthub是开源了的,可以自己抓包或者查看源代码,检查其是否上传敏感数据。
- 付费。目前alinode好像完全免费的,至于以后会不会收费,不知道。
es6基本语法
模块
-
- 总结一下就是,一直用module.exports总不会错的。
-
- 所以说通过
var let const的作用范围是当前模块,而不加修饰的变量定义会造成全局污染,因为模块的作用域其实是函数作用域。
- 所以说通过
为什么包装在全局的时候,项目中使用的时候会找不到。
- https://segmentfault.com/a/1190000019198107
- node扫描包的顺序是,从当前层向外层依次找node_modules文件夹,全局包的安装路径不符合这个规则的,所以找不到。
事件/异步
promise
详情可以看阮一峰老师写的Promise对象
Promise 的设计思想就是,所有异步任务都返回一个Promise实例。
Promise对象的状态:
- 异步操作未完成(pending)
- 异步操作成功(fulfilled)
- 异步操作失败(rejected)
Promise的状态变化的特点:
- 只能从未完成(pending) ——> 操作成功(fulfilled)/ 操作失败(rejected)。
- 状态一旦发生变化就不会再次改变。
JavaScript提供原生的构造函数,用来生成Promise实例
1
2
3
4
5
6
7
8
9var promise = new Promise(function (resolve, reject) {
// ...
if (/* 异步操作成功 */){
resolve(value);
} else { /* 异步操作失败 */
reject(new Error());
}
});- resolve的作用是把promise实例的状态从未完成(pending) ——> 操作成功(fulfilled)
- rejected的作用是把promise实例的状态从未完成(pending) ——>操作失败(rejected)
异常捕获
1
2
3
4
5
6auto.getData().then(function (results) {
res.send(results);
}, next);
auto.getData().then(function (results) {
res.send(results);
}).catch(next);- 上述两种写法,第一种写法,只能捕获getData()产生的错误,而第二种写法,可以捕获到整个Promise调用链中的错误。
Events
Events是node.js一个非常重要的 core 模块,比如Stream是基于Events实现的, 而fs,net,http等模块都依赖Stream- 另外可以注意一下的是, 有些同学喜欢用 emitter 来监控某些类的状态, 但是在这些类释放的时候可能会忘记释放 emitter, 而这些类的内部可能持有该 emitter 的 listener 的引用从而导致内存泄漏
阻塞/异步
如何判断接口是否异步? 是否只要有回调函数就是异步?
- 看文档
- console.log 打印看看
- 看是否有 IO 操作
阻塞/非阻塞?异步同步?
- 之前面试被问到过,我的理解如下:
- 假设面试完之后,HR给你打电话,告诉你你被录用了。如果你直接告诉了HR你同意或是拒绝,这就是**
同步,如果你说,我现在没时间,过两天再给你答复,这样就是异步;HR在听到你说过两天给他答复时,她继续去给下一个求职者打电话,这样就是非阻塞,如果HR什么都不敢,一直等着你的回复,这就是阻塞**。 - 我不知道理解的有没有问题。。。知乎上搜了很多,大概也是这么个意思。
死循环对js的项目会有什么影响?
- Node.js 中执行 js 代码的过程是单线程的. 只有当前代码都执行完, 才会切入事件循环, 然后从事件队列中 pop 出下一个回调函数开始执行代码。
- 所以死循环就会让服务器停止所有响应,如果死循环里面有其他操作可能就会栈溢出或者内存溢出直接挂掉。
一个简单的sleep函数
1
2
3
4
5
6function sleep(ms) {
var start = Date.now(), expire = start + ms;
while (Date.now() < expire) ;
return;
}如何实现一个异步的 reduce?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16(async () => {
let getPromise = (key) => new Promise(resolve => {
setTimeout(() => {
console.log('reduce item:', key ** 2)
resolve(key ** 2)
}, 1000)
})
console.log('reduce start')
console.log('reduce result:', await [1, 2, 3, 4].reduce((result, cursor) => {
return async () => {
return await result() + await getPromise(cursor)
}
}, async () => 0)())
console.log('reduce end')
})()
Event-loop
不要混淆nodejs和浏览器中的event loop是我在cnode论坛上看到的一篇有关时间循环的文章。而且这个东西只要你搞清楚下面那几个异步调用的执行顺序,更深的东西也没必要花时间去研究,意义不大。。
timers:执行
setTimeout()和setInterval()中到期的callback。I/O callbacks:上一轮循环中有少数的I/Ocallback会被延迟到这一轮的这一阶段执行
idle, prepare:仅内部使用
poll:最为重要的阶段,执行I/O callback,在适当的条件下会阻塞在这个阶段
check:执行
setImmediate的callbackclose callbacks:执行close事件的callback,例如
socket.on("close",func)补充说明:
process.nextTick()在每个阶段结束都会执行。如果你仅仅是想产生一个异步调用,建议使用setImmediate。
看懂下面这段的输出就大概知道执行顺序了,另外知乎的这篇文章也可以帮你理解。
我们分析一下:
- setTimeout 和 setInterval 是回调执行是在 Timers阶段,setImmediate 回调执行是在 check 阶段,并且他们都会被放到下一轮执行,所以肯定是后三个输出,并且 setImmediate 在最后。
- Promise.then 和 process.nextTick,点击上面那个《不要混淆nodejs和浏览器中的event loop》,根据大佬分析可知, process.nextTick是在每一个阶段结尾都会执行,并且在结尾调用了
runMicrotasks();//microtasks将会在此时执行,例如Promise,所以Promise.then是在process.nextTick后面一丢丢执行。- setTimeout 和 setInterval 执行顺序取决于谁先被放进回调队列。这样输出结果就完全解释的通了。
1 | setTimeout(() => { |
并行/并发
转一张图,其实这里大部分东西都是根据eleme那个大佬发的内容整理的,最后我会把引用的文章或帖子尽量都贴出来。
什么是并发: 两个人用一个咖啡机。
什么是并行:两队人用两个咖啡机。
node中的并发:
- Node.js 通过事件循环来挨个抽取事件队列中的一个个 Task 执行, 从而避免了传统的多线程情况下
2个队列对应 1个咖啡机的时候上下文切换以及资源争抢/同步的问题。 - node的大并发只是拿到请求就扔进队列而已,并不是自己处理能力有多厉害,所以说适合I/O密集型业务,CPU密集型业务的话需要一定的优化(算法,c++扩展)并且没有那么擅长把。。
- Node.js 通过事件循环来挨个抽取事件队列中的一个个 Task 执行, 从而避免了传统的多线程情况下
node的并行: 通过
cluster来添加一个咖啡机。
进程
了解进程前,先看看进程和线程的区别
process
前文提到的process.nextTick也是process的一个方法,那么递归调用呢?
1
2
3
4
5
6function test() {
console.log('nextTick');
process.nextTick(() => test());
}
// 会不停的输出nextTick,因为这样永远跳不出本轮循环。1
2
3
4
5
6function test() {
console.log('timeout');
setTimeout(() => test(), 0);
}
// 也会不停的输出timeout,但是不会阻塞其它异步回调,因为总是插入到下一次循环。进程的当前工作目录是什么? 有什么作用?
- 当前进程启动的目录, 通过
process.cwd()获取当前工作目录 (current working directory), 通常是命令行启动的时候所在的目录 (也可以在启动时指定), 文件操作等使用相对路径的时候会相对当前工作目录来获取文件.
- 当前进程启动的目录, 通过
标准流
process.stderr, process.stdout 以及 process.stdin 三个标准流
console.log是同步还是异步?console.log同步还是异步要取决于操作系统。详见进程 I/O 的注意事项
如何实现一个 console.log?可以参见Console 模块解读及简单实现
- 其实核心的话就是这句
process.stdout.**write**(params);。。
- 其实核心的话就是这句
Child Process
spawn() 启动一个子进程来执行命令
- options.detached 父进程死后是否允许子进程存活
- options.stdio 指定子进程的三个标准流
spawnSync() 同步版的 spawn, 可指定超时, 返回的对象可获得子进程的情况
exec() 启动一个子进程来执行命令, 带回调参数获知子进程的情况, 可指定进程运行的超时时间
execSync() 同步版的 exec(), 可指定超时, 返回子进程的输出 (stdout)
execFile() 启动一个子进程来执行一个可执行文件, 可指定进程运行的超时时间
execFileSync() 同步版的 execFile(), 返回子进程的输出, 如何超时或者 exit code 不为 0, 会直接 throw Error
fork() 加强版的 spawn(), 返回值是 ChildProcess 对象可以与子进程交互
child_process.fork 与 POSIX 的 fork 有什么区别?
- Node.js 的
child_process.fork()在 Unix 上的实现最终调用了 POSIX fork(2), 而 POSIX 的 fork 需要手动管理子进程的资源释放 (waitpid), child_process.fork 则不用关心这个问题, Node.js 会自动释放, 并且可以在 option 中选择父进程死后是否允许子进程存活。
- Node.js 的
child.kill与child.send的区别?- 前者基于信号系统,后者基于IPC通道。
父进程或子进程的死亡是否会影响对方? 什么是孤儿进程?
- 子进程死亡不会影响父进程, 不过子进程死亡时(线程组的最后一个线程,通常是“领头”线程死亡时),会向它的父进程发送死亡信号. 反之父进程死亡, 一般情况下子进程也会随之死亡, 但如果此时子进程处于可运行态、僵死状态等等的话, 子进程将被
进程1(init 进程)收养,从而成为孤儿进程. 另外, 子进程死亡的时候(处于“终止状态”),父进程没有及时调用wait()或waitpid()来返回死亡进程的相关信息,此时子进程还有一个PCB残留在进程表中,被称作僵尸进程。
- 子进程死亡不会影响父进程, 不过子进程死亡时(线程组的最后一个线程,通常是“领头”线程死亡时),会向它的父进程发送死亡信号. 反之父进程死亡, 一般情况下子进程也会随之死亡, 但如果此时子进程处于可运行态、僵死状态等等的话, 子进程将被
Cluster
- worker 进程是由 child_process.fork() 方法创建的, 所以可以通过 IPC 在主进程和子进程之间相互传递服务器句柄。
- cluster 模块提供了两种分发连接的方式。
- 第一种方式 (默认方式, 不适用于 windows), 通过时间片轮转法(round-robin)分发连接. 主进程监听端口, 接收到新连接之后, 通过时间片轮转法来决定将接收到的客户端的 socket 句柄传递给指定的 worker 处理. 至于每个连接由哪个 worker 来处理, 完全由内置的循环算法决定
- 第二种方式是由主进程创建 socket 监听端口后, 将 socket 句柄直接分发给相应的 worker, 然后当连接进来时, 就直接由相应的 worker 来接收连接并处理
- 使用第二种方式时理论上性能应该较高, 然后时间上存在负载不均衡的问题, 比如通常 70% 的连接仅被 8 个进程中的 2 个处理, 而其他进程比较清闲
进程间通信
IPC (Inter-process communication) 进程间通信技术. 常见的进程间通信技术列表如下:
| 类型 | 无连接 | 可靠 | 流控制 | 优先级 |
|---|---|---|---|---|
| 普通PIPE | N | Y | Y | N |
| 命名PIPE | N | Y | Y | N |
| 消息队列 | N | Y | Y | N |
| 信号量 | N | Y | Y | Y |
| 共享存储 | N | Y | Y | Y |
| UNIX流SOCKET | N | Y | Y | N |
| UNIX数据包SOCKET | Y | Y | N | N |
在 IPC 通道建立之前, 父进程与子进程是怎么通信的? 如果没有通信, 那 IPC 是怎么建立的?
在通过 child_process 建立子进程的时候, 是可以指定子进程的 env (环境变量) 的. 所以 Node.js 在启动子进程的时候, 主进程先建立 IPC 频道, 然后将 IPC 频道的 fd (文件描述符) 通过环境变量 (NODE_CHANNEL_FD) 的方式传递给子进程, 然后子进程通过 fd 连上 IPC 与父进程建立连接
什么是 IPC 通信,如何建立 IPC 通信?什么场景下需要用到 IPC 通信?
IPC (Inter-process communication) ,即进程间通信技术,由于每个进程创建之后都有自己的独立地址空间,实现 IPC 的目的就是为了进程之间资源共享访问。实现 IPC 的方式有多种:管道、消息队列、信号量、Domain Socket,Node.js 通过 pipe 来实现。
守护进程
什么是守护进程?
简单说就是不会因为用户退出终端而停止运行的进程。
pm2就是一个以守护进程启动nodejs应用的工具,如何编写一个守护进程?
IO
Buffer
什么是Buffer?
- Buffer 是 Node.js 中用于处理二进制数据的类。
- Buffer类的实例非常类似整数数组,但Buffer实例创建之后其
大小是固定不变的。
Buffer支持的字符编码?
- ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ucs2 - utf16le 的别名。
- base64 - Base64 编码。
- latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
- binary - latin1 的别名。
- hex - 将每个字节编码为两个十六进制字符。
创建Buffer实例的方法?
Buffer.alloc(size[, fill[, encoding]]): 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
Buffer.allocUnsafe(size): 返回一个指定大小的 Buffer 实例,但是它不会被初始化,所以它可能包含敏感的数据
Buffer.allocUnsafeSlow(size)
Buffer.from(array): 返回一个被 array 的值初始化的新的 Buffer 实例(传入的 array 的元素只能是数字,不然就会自动被 0 覆盖)
Buffer.from(arrayBuffer[, byteOffset[, length]]): 返回一个新建的与给定的 ArrayBuffer 共享同一内存的 Buffer。
Buffer.from(buffer): 复制传入的 Buffer 实例的数据,并返回一个新的 Buffer 实例
Buffer.from(string[, encoding]): 返回一个被 string 的值初始化的新的 Buffer 实例
1
2
3
4
5
6const buf1 = Buffer.alloc(10);
console.log(buf1); // <Buffer 00 00 00 00 00 00 00 00 00 00>
const buf2 = Buffer.allocUnsafe(10);
console.log(buf2) // <Buffer 4c 46 80 05 01 00 00 00 4c 46>
const buf3 = Buffer.allocUnsafe(10).fill(0);
console.log(buf3); // <Buffer 00 00 00 00 00 00 00 00 00 00>
Buffer常用操作?
写入缓冲区
buf.write(string[, offset[, length]][, encoding])从缓冲区读取数据
buf.toString([encoding[, start[, end]]])将 Buffer 转换为 JSON 对象
buf.toJSON()缓冲区合并
Buffer.concat(list[, totalLength])缓冲区比较
buf.compare(otherBuffer);- 返回值小于 0 。
buf在otherBuffer之前 - 返回值等于 0 。
buf和otherBuffer相同 - 返回值大于 0 。
buf在otherBuffer之后
- 返回值小于 0 。
拷贝缓冲区
buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]])- 把 buf9插入到buf10的第三位。
1
2
3
4
5
6const buf9 = Buffer.from('zmaaaassss')
const buf10 = Buffer.from('ruomu')
console.log(buf9) // <Buffer 7a 6d 61 61 61 61 73 73 73 73>
console.log(buf10) // <Buffer 72 75 6f 6d 75>
buf9.copy(buf10,3)
console.log(buf10); // <Buffer 72 75 6f 7a 6d>
- 把 buf9插入到buf10的第三位。
String Decoder
字符串解码器 (String Decoder) 是一个用于将 Buffer 拿来 decode 到 string 的模块, 是作为 Buffer.toString 的一个补充, 它支持多字节 UTF-8 和 UTF-16 字符。
Stream
流的类型
Writable- 可写入数据的流(例如fs.createWriteStream())。Readable- 可读取数据的流(例如fs.createReadStream())。Duplex- 可读又可写的流(例如net.Socket)。Transform- 在读写过程中可以修改或转换数据的Duplex流(例如zlib.createDeflate())。
Netword
粘包
可以参见网上流传比较广的一个例子, 连续调用两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下几种常见的情况:
- A. 先接收到 data1, 然后接收到 data2 .
- B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部.
- C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据.
- D. 一次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常见的粘包的情况. 而对于处理粘包的问题, 常见的解决方案有:
- 多次发送之前间隔一个等待时间
- 只需要等上一段时间再进行下一次 send 就好, 适用于交互频率特别低的场景. 缺点也很明显, 对于比较频繁的场景而言传输效率实在太低. 不过几乎不用做什么处理。
- 关闭 Nagle 算法
- 关闭 Nagle 算法, 在 Node.js 中你可以通过
socket.setNoDelay()方法来关闭 Nagle 算法, 让每一次 send 都不缓冲直接发送。该方法比较适用于每次发送的数据都比较大 (但不是文件那么大), 并且频率不是特别高的场景. 如果是每次发送的数据量比较小, 并且频率特别高的, 关闭 Nagle 纯属自废武功。
- 关闭 Nagle 算法, 在 Node.js 中你可以通过
- 进行封包/拆包
- 封包/拆包是目前业内常见的解决方案了. 即给每个数据包在发送之前, 于其前/后放一些有特征的数据, 然后收到数据的时候根据特征数据分割出来各个数据包。
UDP
| 协议 | 连接性 | 双工性 | 可靠性 | 有序性 | 有界性 | 拥塞控制 | 传输速度 | 量级 | 头部大小 |
|---|---|---|---|---|---|---|---|---|---|
| TCP | 面向连接 (Connection oriented) | 全双工(1:1) | 可靠 (重传机制) | 有序 (通过SYN排序) | 无, 有粘包情况 | 有 | 慢 | 低 | 20~60字节 |
| UDP | 无连接 (Connection less) | n:m | 不可靠 (丢包后数据丢失) | 无序 | 有消息边界, 无粘包 | 无 | 快 | 高 | 8字节 |
HTTP
- GET 和 POST 有什么区别?
- 只有语义上的区别,你可以不遵守。
- GET产生一个TCP数据包;POST产生两个TCP数据包。但是有些浏览器POST只发一个数据包。
- POST 和 PUT 有什么区别?
- POST 是新建 (create) 资源, 非幂等, 同一个请求如果重复 POST 会新建多个资源。
- PUT 是 Update/Replace, 幂等, 同一个 PUT 请求重复操作会得到同样的结果。
DNS
DNS 模块中 .lookup 与 .resolve 的区别?
方法 功能 同步 网络请求 速度 .lookup(hostname[, options], cb) 通过系统自带的 DNS 缓存 (如 /etc/hosts)同步 无 快 .resolve(hostname[, rrtype], cb) 通过系统配置的 DNS 服务器指定的记录 (rrtype指定) 异步 有 慢 当你要解析一个域名的 ip 时, 通过 .lookup 查询直接调用
getaddrinfo来拿取地址, 速度很快, 但是如果本地的 hosts 文件被修改了, .lookup 就会拿 hosts 文件中的地方, 而 .resolve 依旧是外部正常的地址。
hosts 文件是什么? 什么叫 DNS 本地解析?
- hosts 文件是个没有扩展名的系统文件, 其作用就是将网址域名与其对应的 IP 地址建立一个关联“数据库”, 当用户在浏览器中输入一个需要登录的网址时, 系统会首先自动从 hosts 文件中寻找对应的IP地址。
RPC
RPC (Remote Procedure Call Protocol) 基于 TCP/IP 来实现调用远程服务器的方法, 与 http 同属应用层. 常用于构建集群, 以及微服务
常见的RPC方式
- Thrift
- Thrift是一种由FaceBook为“大规模跨语言服务”开发的接口描述语言](https://zh.wikipedia.org/wiki/接口描述语言)和二进制通讯协议。
- HTTP
- 使用 HTTP 协议来进行 RPC 调用也是很常见的, 相比 TCP 连接, 通过通过 HTTP 的方式性能会差一些, 但是在使用以及调试上会简单一些. 近期比较有名的框架参见 gRPC。
- MQ
- 使用消息队列 (Message Queue) 来进行 RPC 调用 (RPC over mq) 在业内有不少例子, 比较适合业务解耦/广播/限流等场景.
OS
TTY
“tty” 原意是指 “teletype” 即打字机, “pty” 则是 “pseudo-teletype” 即伪打字机. 在 Unix 中, /dev/tty* 是指任何表现的像打字机的设备, 例如终端 (terminal)。
使用w命令可以看到当前登录的用户情况
1
2
3
4USER TTY FROM LOGIN@ IDLE WHAT
zhangming console - 27 420 13days -
zhangming s002 - 日17 - -zsh
zhangming s003 - 14:35 - w
OS模块
| os.EOL | 根据当前系统, 返回当前系统的 End Of Line |
|---|---|
| os.arch() | 返回当前系统的 CPU 架构, 如 'x86' 和 'x64' |
| os.constants | 返回系统常量 |
| os.cpus() | 返回 CPU 每个核的信息 |
| os.endianness() | 返回 CPU 字节序, 如果是大端字节序返回 BE, 小端字节序则 LE |
| os.freemem() | 返回系统空闲内存的大小, 单位是字节 |
| os.homedir() | 返回当前用户的根目录 |
| os.hostname() | 返回当前系统的主机名 |
| os.loadavg() | 返回负载信息 |
| os.networkInterfaces() | 返回网卡信息 (类似 ifconfig) |
| os.platform() | 返回编译时指定的平台信息, 如 win32, linux, 同 process.platform() |
| os.release() | 返回操作系统的分发版本号 |
| os.tmpdir() | 返回系统默认的临时文件夹 |
| os.totalmem() | 返回总内存大小(同内存条大小) |
| os.type() | 根据 [uname](https://en.wikipedia.org/wiki/Uname#Examples) 返回系统的名称 |
| os.uptime() | 返回系统的运行时间,单位是秒 |
| os.userInfo([options]) | 返回当前用户信息 |
不同系统的换行符(EOL)的区别
| 符号 | 系统 |
|---|---|
| LF(\n) | 在 Unix 或 Unix 相容系统 (GNU/Linux, AIX, Xenix, Mac OS X, …)、BeOS、Amiga、RISC OS |
| CR+LF | MS-DOS、微软视窗操作系统 (Microsoft Windows)、大部分非 Unix 的系统 |
| CR (\r) | Apple II 家族, Mac OS 至版本9 |
Path
Node.js 内置的 path 是用于处理路径问题的模块. 不过众所周知, 路径在不同操作系统下又不可调和的差异。所以不要自己随便拼接路径,要使用Path.join()或者Path.resolve()。
| POSIX | 值 | Windows | 值 |
|---|---|---|---|
| path.posix.sep | '/' |
path.win32.sep | '\\' |
| path.posix.normalize(‘/foo/bar//baz/asdf/quux/..’) | '/foo/bar/baz/asdf' |
path.win32.normalize(‘C:\temp\foo\bar..') | 'C:\\temp\\foo\\' |
| path.posix.basename(‘/tmp/myfile.html’) | 'myfile.html' |
path.win32.basename(‘C:\temp\myfile.html’) | 'myfile.html' |
| path.posix.join(‘/asdf’, ‘/test.html’) | '/asdf/test.html' |
path.win32.join(‘/asdf’, ‘/test.html’) | '\\asdf\\test.html' |
| path.posix.relative(‘/root/a’, ‘/root/b’) | '../b' |
path.win32.relative(‘C:\a’, ‘c:\b’) | '..\\b' |
| path.posix.isAbsolute(‘/baz/..’) | true |
path.win32.isAbsolute(‘C:\foo..’) | true |
| path.posix.delimiter | ':' |
path.win32.delimiter | ',' |
| process.env.PATH | '/usr/bin:/bin' |
process.env.PATH | C:\Windows\system32;C:\Program Files\node\' |
| PATH.split(path.posix.delimiter) | ['/usr/bin', '/bin'] |
PATH.split(path.win32.delimiter) | ['C:\\Windows\\system32', 'C:\\Program Files\\node\\'] |
环境变量
| 环境变量 | 简介 |
|---|---|
NODE_DEBUG=module[,…] |
指定要打印调试信息的核心模块列表 |
NODE_PATH=path[:…] |
指定搜索目录模块路径的前缀列表 |
NODE_DISABLE_COLORS=1 |
关闭 REPL 的颜色显示 |
NODE_ICU_DATA=file |
ICU (Intl object) 数据路径 |
NODE_REPL_HISTORY=file |
持久化存储REPL历史文件的路径 |
NODE_TTY_UNSAFE_ASYNC=1 |
设置为1时, 将同步操作 stdio (如 console.log 变成同步) |
NODE_EXTRA_CA_CERTS=file |
指定 CA (如 VeriSign) 的额外证书路径 |
负载
负载是衡量服务器运行状态的一个重要概念. 通过负载情况, 我们可以知道服务器目前状态是清闲, 良好, 繁忙还是即将 crash。
PM2管理node进程,pm2入门
错误处理/调试
Errors
在 Node.js 中的错误主要有一下四种类型:
| 错误 | 名称 | 触发 |
|---|---|---|
| Standard JavaScript errors | 标准 JavaScript 错误 | 由错误代码触发 |
| System errors | 系统错误 | 由操作系统触发 |
| User-specified errors | 用户自定义错误 | 通过 throw 抛出 |
| Assertion errors | 断言错误 | 由 assert 模块触发 |
其中标准的 JavaScript 错误常见有:
- EvalError: 调用 eval() 出现错误时抛出该错误
- SyntaxError: 代码不符合 JavaScript 语法规范时抛出该错误
- RangeError: 数组越界时抛出该错误
- ReferenceError: 引用未定义的变量时抛出该错误
- TypeError: 参数类型错误时抛出该错误
- URIError: 误用全局的 URI 处理函数时抛出该错误
在 Node.js 中错误处理主要有一下几种方法:
callback(err, data) 回调约定
throw / try / catch
EventEmitter 的 error 事件
vError模块让 Error 一层层封装, 并在每一层将错误的信息一层层的包上, 最后拿到的 Error 直接可以从 message 中获取用于定位问题的关键信息.
测试
测试方法
黑盒测试
黑盒测试 (Black-box Testing), 测试应用程序的功能, 而不是其内部结构或运作. 测试者不需了解代码、内部结构等, 只需知道什么是应用应该做的事, 即当键入特定的输入, 可得到一定的输出. 测试者通过选择有效输入和无效输入来验证是否正确的输出. 此测试方法可适合大部分的软件测试, 例如集成测试 (Integration Testing) 以及系统测试 (System Testing)。
白盒测试
白盒测试 (White-box Testing) 测试应用程序的内部结构或运作, 而不是测试应用程序的功能 (即黑盒测试). 在白盒测试时,以编程语言的角度来设计测试案例. 白盒测试可以应用于单元测试 (Unit Testing)、集成测试 (Integration Testing) 和系统的软件测试流程, 可测试在集成过程中每一单元之间的路径, 或者主系统跟子系统中的测试。
单元测试
单元测试 (Unit Testing) 是白盒测试的一种, 用于针对程序模块进行正确性检验的测试工作. 单元 (Unit) 是指最小可测试的部件. 在过程化编程中, 一个单元就是单个程序、函数、过程等; 对于面向对象编程, 最小单元就是方法, 包括基类、抽象类、或者子类中的方法。
覆盖率
覆盖率通常由四个维度贡献:
行覆盖率 (line coverage) 是否每一行都执行了?
函数覆盖率 (function coverage) 是否每个函数都调用了?
分支覆盖率 (branch coverage) 是否每个if代码块都执行了?
语句覆盖率 (statement coverage) 是否每个语句都执行了?
常用的测试覆盖率框架 istanbul
常见测试工具
- Mocha
- ava
- Jest
压力测试
压力测试 (Stress testing), 是保证系统稳定性的一种测试方法. 通过预估系统所需要承载的 QPS, TPS 等指标, 然后通过如 Jmeter 等压测工具模拟相应的请求情况, 来验证当前应能能否达到目标。